
کد خبر:۱۳۳۰۵۳۴
کشف شگفتانگیز در هوش مصنوعی: حافظه و استدلال در مغز ماشینی از هم جدا هستند!
محققان کشف کردهاند که مهارتهای حافظه و استدلال آنها بخشهای متمایزی از معماری داخلی آنها را اشغال میکند. بینش آنها میتواند به ایمنتر و قابل اعتمادتر شدن هوش مصنوعی کمک کند.
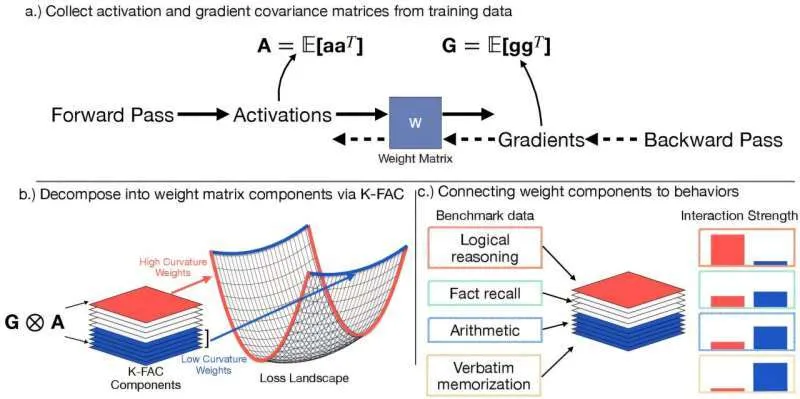
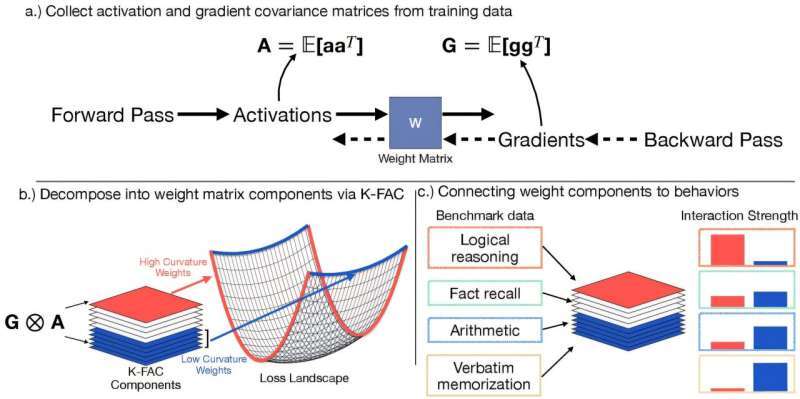
به گزارش خبرنگار دانش و فناوری خبرگزاری دانشجو، محققانی که در حال مطالعه چگونگی یادگیری و به خاطر سپردن اطلاعات در مدلهای بزرگ هوش مصنوعی مانند ChatGPT هستند، کشف کردهاند که مهارتهای حافظه و استدلال آنها بخشهای متمایزی از معماری داخلی آنها را اشغال میکند. بینش آنها میتواند به ایمنتر و قابل اعتمادتر شدن هوش مصنوعی کمک کند.
مدلهای هوش مصنوعی که بر روی مجموعه دادههای عظیم آموزش دیدهاند، حداقل به دو ویژگی پردازشی اصلی متکی هستند. اولین مورد حافظه است که به سیستم اجازه میدهد اطلاعات را بازیابی و بازگو کند. مورد دوم استدلال است که با بهکارگیری اصول تعمیمیافته و الگوهای آموختهشده، مسائل جدید را حل میکند. اما تاکنون مشخص نبود که آیا حافظه و هوش عمومی هوش مصنوعی در یک مکان ذخیره میشوند یا خیر؛ بنابراین محققان در استارتاپ Goodfire.ai تصمیم گرفتند ساختار داخلی مدلهای بزرگ زبانی و بینایی را بررسی کنند تا نحوه عملکرد آنها را درک کنند.
نقشهبرداری از مغز هوش مصنوعی
ابتدا، این تیم از یک تکنیک ریاضی به نام K-FAC (انحنای تقریبی کرونکر-فاکتوردار) برای شناسایی اجزای پردازشی خاص مسئول قابلیتهای مختلف، به ویژه حفظ کردن طوطیوار در مسیرهای با انحنای کم (خطوط حافظه باریک و تخصصی) و استدلال انعطافپذیر در نواحی با انحنای بالا (اجزای پردازشی گسترده و مشترک) استفاده کرد.
سپس بخشهایی از هوش مصنوعی مرتبط با حفظ کردن را خاموش کردند و مدل را در وظایف مختلف آزمایش کردند. این وظایف شامل پاسخ دادن به سؤالات واقعی و حل مسائل جدید بود. این به آنها اجازه داد تا نشان دهند که وقتی حافظه غیرفعال میشود، مدلها همچنان میتوانند از مهارتهای استدلال خود استفاده کنند، که نشان میدهد این دو عملکرد بخشهای جداگانهای از معماری داخلی هوش مصنوعی را اشغال میکنند.
محققان در مقاله خود که در سرور پیشچاپ arXiv منتشر شده است، نوشتند: «رویکرد هرس مبتنی بر انحنای ما، بدون نیاز به دادههای آموزشی تحت نظارت، به طور مؤثر، به بهترین شکل، به خاطر سپردن را در هر دو اندازه مدل کاهش میدهد و به طور قابل توجهی به تعمیم بهتری برای محتوای به خاطر سپرده شده نامرئی دست مییابد.»
فرآیند غیرفعال کردن حافظه، یک بدهبستان شگفتانگیز را آشکار کرد. در حالی که حل مسئله عمومی دستنخورده باقی ماند، مهارتهایی که هوش مصنوعی برای ریاضیات و یادآوری حقایق جداگانه استفاده میکرد، به شدت تحت تأثیر قرار گرفتند. نویسندگان گفتند: «بازیابی حقایق حساب و کتاب بسته بیشتر به جهتهای کم انحنا متکی هستند و به طور نامتناسبی تحت تأثیر ویرایشها قرار میگیرند، در حالی که استدلال منطقی کتاب باز و غیرعددی تا حد زیادی حفظ شده یا گاهی اوقات بهبود مییابد.»
ایمنتر کردن هوش مصنوعی
دانستن دقیق نحوهی عملکرد هوش مصنوعی، کلید بهبود ایمنی و افزایش اعتماد عمومی خواهد بود. یکی از مشکلات مدلهای هوش مصنوعی که دادهها را به خاطر میسپارند این است که ممکن است اطلاعات خصوصی یا متن دارای حق چاپ را فاش کنند. همچنین، این به خاطر سپردن میتواند منجر به حفظ تعصبات مضر یا محتوای سمی شود.
اما اگر مهندسان بتوانند حقایق حفظشدهی طوطیوار و مسیرهای تخصصی را بدون تأثیر بر هوش عمومی هوش مصنوعی، دقیقاً هدف قرار داده و حذف کنند، میتوان این مشکلات را کاهش داد. درک این مسیرهای حافظه همچنین میتواند با کاهش میزان فضای شبکهی مورد نیاز، مدلهای هوش مصنوعی را کارآمدتر و ارزانتر کند.
لینک کپی شد
گزارش خطا
اخبار مرتبط
