وقتی واژهها مهم میشوند/ سنجش و بهبود قطعیت در زبان پزشکی
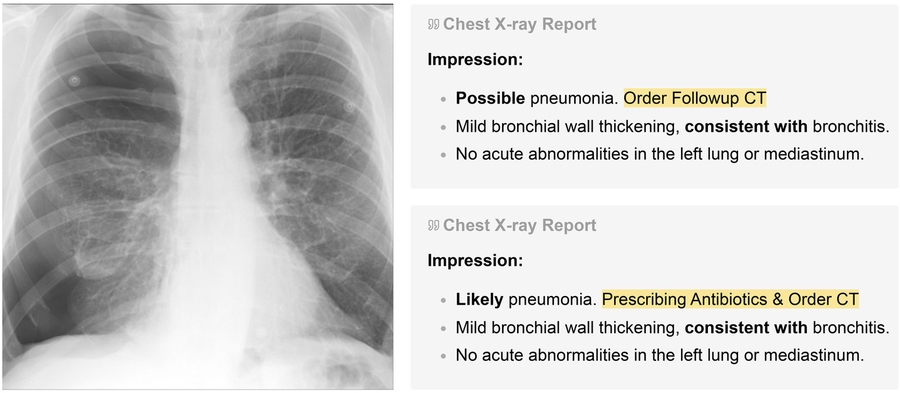
به گزارش گروه دانشگاه خبرگزاری دانشجو، رادیولوژیستها به دلیل ابهام ذاتی تصویر از عبارات طبیعی قطعیت استفاده میکنند. این عبارات بر مراقبت از بیمار تأثیر میگذارند - «ممکن است» ممکن است باعث پیگیری فوری شود، در حالی که «احتمالا» میتواند منجر به درمان فوری شود. کار جدید بررسی میکند که این عبارات تا چه حد قطعیت تشخیصی را با دقت بیان میکنند و راههایی را برای بهبود کالیبراسیون زبان رادیولوژیستها برای انعکاس بهتر نتایج دنیای واقعی بررسی میکند.
به دلیل ابهام ذاتی در تصاویر پزشکی مانند اشعه ایکس، رادیولوژیستها اغلب از کلماتی مانند "ممکن است" یا "احتمالا" هنگام توصیف وجود یک آسیب شناسی خاص مانند ذات الریه استفاده میکنند.
اما آیا کلماتی که رادیولوژیستها برای بیان سطح اعتماد به نفس خود به کار میبرند، نشان دهنده این است که هر چند وقت یکبار یک آسیب شناسی خاص در بیماران رخ میدهد؟ یک مطالعه جدید نشان میدهد که وقتی رادیولوژیستها در مورد آسیبشناسی خاصی با استفاده از عبارتی مانند "بسیار محتمل" اعتماد میکنند، تمایل دارند بیش از حد اعتماد به نفس داشته باشند و برعکس زمانی که اعتماد کمتری را با استفاده از کلمهای مانند "احتمالا" ابراز میکنند.
با استفاده از دادههای بالینی، یک تیم چند رشتهای از محققان MIT با همکاری محققان و پزشکان در بیمارستانهای وابسته به دانشکده پزشکی هاروارد چارچوبی را برای تعیین کمیت رادیولوژیستها در هنگام ابراز اطمینان با استفاده از اصطلاحات زبان طبیعی ایجاد کردند.
آنها از این رویکرد برای ارائه پیشنهادهای واضحی استفاده کردند که به رادیولوژیستها کمک میکند عبارات قطعی را انتخاب کنند که قابلیت اطمینان گزارش بالینی آنها را بهبود میبخشد. آنها همچنین نشان دادند که همین تکنیک میتواند به طور موثری کالیبراسیون مدلهای زبان بزرگ را با تراز کردن بهتر کلماتی که مدلها برای بیان اطمینان با دقت پیشبینیهایشان استفاده میکنند، اندازهگیری و بهبود بخشد.
این چارچوب جدید با کمک به رادیولوژیستها برای توصیف دقیقتر احتمال پاتولوژیهای خاص در تصاویر پزشکی، میتواند قابلیت اطمینان اطلاعات بالینی حیاتی را بهبود بخشد.
پیکی وانگ، دانشجوی کارشناسی ارشد MIT و نویسنده ارشد مقاله در مورد این تحقیق، میگوید: کلماتی که رادیولوژیستها استفاده میکنند مهم هستند. آنها بر نحوه مداخله پزشکان، از نظر تصمیمگیری برای بیمار، تأثیر میگذارند. اگر این پزشکان بتوانند در گزارش خود قابل اعتمادتر باشند، بیماران ذینفع نهایی خواهند بود.
نویسنده ارشد پولینا گولاند، استاد سانلین و پریسیلا چو در مهندسی برق و علوم کامپیوتر (EECS)، محقق اصلی در آزمایشگاه علوم کامپیوتر و هوش مصنوعی MIT (CSAIL) و رهبر گروه چشم انداز پزشکی به او در این مقاله میپیوندند؛ و همچنین باربارا دی. لام، همکار بالینی در مرکز پزشکی Beth Israel Deaconess. Yingcheng Liu، دانشجوی کارشناسی ارشد MIT; آمنه عسگری ترقی، پژوهشگر در ماساچوست جنرال بریگام (MGB) ; Rameswar Panda، یکی از کارکنان تحقیقاتی MIT-IBM Watson AI Lab. ویلیامام. ولز، استاد رادیولوژی در MGB و دانشمند پژوهشی در CSAIL؛ و تینا کاپور، استادیار رادیولوژی در MGB. این تحقیق در کنفرانس بینالمللی نمایشهای یادگیری ارائه خواهد شد.
رمزگشایی عدم قطعیت در کلمات
یک رادیولوژیست که گزارشی در مورد عکس برداری از قفسه سینه مینویسد ممکن است بگوید این تصویر یک ذات الریه "احتمالی" را نشان میدهد، که عفونتی است که کیسههای هوایی در ریهها را ملتهب میکند. در این صورت، پزشک میتواند برای تایید تشخیص، سی تی اسکن بعدی را تجویز کند.
با این حال، اگر رادیولوژیست بنویسد که اشعه ایکس یک ذات الریه "احتمالی" را نشان میدهد، پزشک ممکن است فوراً درمان را شروع کند، مانند تجویز آنتی بیوتیک، در حالی که هنوز آزمایشهای اضافی را برای ارزیابی شدت تجویز میکند.
وانگ میگوید تلاش برای اندازهگیری کالیبراسیون یا قابلیت اطمینان واژههای زبان طبیعی مبهم مانند «احتمالا» و «احتمالا» چالشهای زیادی را به همراه دارد.
روشهای کالیبراسیون موجود معمولاً بر امتیاز اطمینان ارائهشده توسط یک مدل هوش مصنوعی تکیه میکنند، که نشاندهنده احتمال تخمینی مدل برای درست بودن پیشبینی آن است.
به عنوان مثال، یک برنامه هواشناسی ممکن است ۸۳ درصد احتمال باران فردا را پیش بینی کند. اگر در تمام مواردی که احتمال بارش باران را ۸۳ درصد پیشبینی میکند، تقریباً ۸۳ درصد مواقع باران ببارد، آن مدل به خوبی کالیبره شده است.
وانگ میگوید: «اما انسانها از زبان طبیعی استفاده میکنند، و اگر این عبارات را به یک عدد نگاشت کنیم، توصیف دقیقی از دنیای واقعی نیست. اگر فردی بگوید که یک رویداد "محتمل" است، لزوماً به احتمال دقیق آن فکر نمیکند، مثلاً ۷۵ درصد.
رویکرد محققان به جای تلاش برای ترسیم عبارات قطعیت به یک درصد واحد، آنها را به عنوان توزیع احتمال در نظر میگیرد. یک توزیع محدوده مقادیر ممکن و احتمالات آنها را توصیف میکند - به منحنی زنگ کلاسیک در آمار فکر کنید.
وانگ میافزاید: این تفاوتهای ظریف بیشتری از معنای هر کلمه را نشان میدهد.
ارزیابی و بهبود کالیبراسیون
محققان از کارهای قبلی که رادیولوژیستها را مورد بررسی قرار میدادند برای به دست آوردن توزیع احتمالی که با هر عبارت قطعیت تشخیصی مطابقت دارد، از "بسیار محتمل" تا "مطابق با" استفاده کردند.
به عنوان مثال، از آنجایی که رادیولوژیستهای بیشتری معتقدند که عبارت "سازگار با" به معنای وجود یک آسیب شناسی در یک تصویر پزشکی است، توزیع احتمال آن به شدت به اوج بالایی میرسد و بیشتر مقادیر در محدوده ۹۰ تا ۱۰۰ درصد قرار میگیرند.
در مقابل، عبارت «ممکن است نشان دهد» عدم قطعیت بیشتری را منتقل میکند که منجر به توزیع گستردهتر و زنگشکل با محوریت حدود ۵۰ درصد میشود.
روشهای معمولی کالیبراسیون را با مقایسه میزان همسویی نمرات احتمال پیشبینیشده مدل با تعداد واقعی نتایج مثبت ارزیابی میکنند.
رویکرد محققین از چارچوب کلی یکسانی پیروی میکند، اما آن را برای توضیح این واقعیت گسترش میدهد که عبارات قطعی به جای احتمالات، توزیع احتمالات را نشان میدهند.
برای بهبود کالیبراسیون، محققان یک مسئله بهینهسازی را فرمولبندی و حل کردند که تعداد دفعات استفاده از عبارات خاص را تنظیم میکند تا اطمینان را با واقعیت همسوتر کند.
آنها یک نقشه کالیبراسیون به دست آوردند که اصطلاحات قطعی را پیشنهاد میکند که رادیولوژیست باید برای دقیقتر کردن گزارشها برای یک آسیب شناسی خاص استفاده کند.
وانگ توضیح میدهد: «شاید، برای این مجموعه داده، اگر هر بار که رادیولوژیست میگوید ذاتالریه وجود دارد، به جای آن عبارت را به «احتمالاً وجود دارد» تغییر میدهند، در آن صورت کالیبرهشدهتر میشوند.
هنگامی که محققان از چارچوب خود برای ارزیابی گزارشهای بالینی استفاده کردند، دریافتند که رادیولوژیستها عموماً هنگام تشخیص بیماریهای رایج مانند آتلکتازی اعتماد بهنفس نداشتند، اما در مورد شرایط مبهمتری مانند عفونت بیش از حد اعتماد به نفس داشتند.
علاوه بر این، محققان قابلیت اطمینان مدلهای زبانی را با استفاده از روش خود ارزیابی کردند و نمایش دقیقتری از اطمینان نسبت به روشهای کلاسیک که بر امتیازات اطمینان تکیه میکنند ارائه کردند.
"بسیاری از اوقات، این مدلها از عباراتی مانند "حتما" استفاده میکنند. اما از آنجایی که آنها در پاسخهای خود بسیار مطمئن هستند، این افراد را تشویق نمیکند که صحت اظهارات خود را تأیید کنند.» وانگ میافزاید.
در آینده، محققان قصد دارند به همکاری با پزشکان به امید بهبود تشخیص و درمان ادامه دهند. آنها در تلاشند تا مطالعه خود را گسترش دهند تا دادههای سی تی اسکن شکم را شامل شود.
علاوه بر این، آنها علاقهمند به مطالعه چگونگی پذیرش رادیولوژیستها نسبت به پیشنهادات بهبود کالیبراسیون هستند و اینکه آیا آنها میتوانند به طور ذهنی استفاده خود از عبارات قطعیت را به طور موثر تنظیم کنند.
آتل بی. کار کردن این رویکرد پتانسیل بهبود دقت و ارتباطات رادیولوژیستها را دارد که به بهبود مراقبت از بیمار کمک میکند.
این کار تا حدی توسط کمک هزینه تحصیلی Takeda، آزمایشگاه هوش مصنوعی MIT-IBM Watson، برنامه MIT CSAIL Wistrom و کلینیک MIT Jameel تامین شد.